


Azure Well-Architected Framework: Reliability Best Practices
To provide a comprehensive overview of the Reliability pillar within the Azure Well-Architected Framework, focusing on key principles, best practices, and service-specific considerations for building

Reliability isn’t just a checkbox—it’s a commitment to keeping applications resilient, always available, and prepared for the unexpected. In this guide, we’ll explore best practices for building highly reliable systems in Azure using the Azure Well-Architected Framework.
💡 Key Takeaway: "Failures are inevitable, but downtime doesn’t have to be"
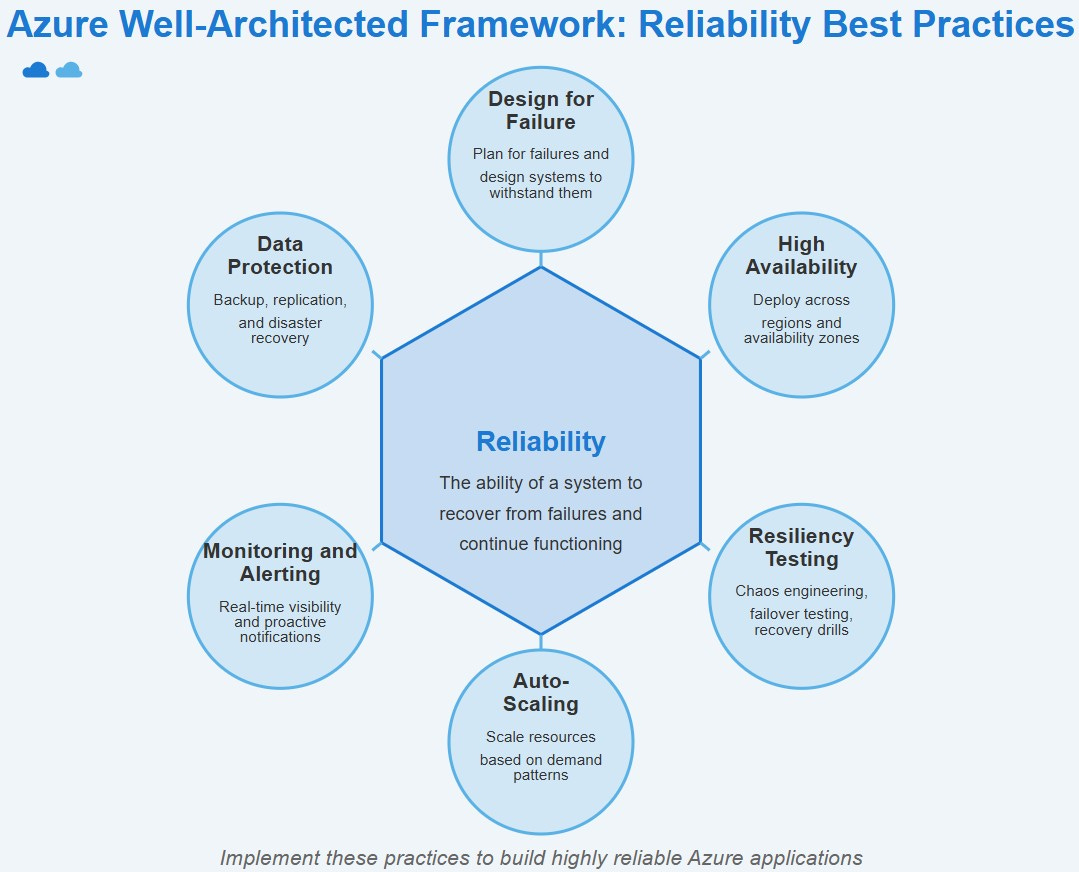
1. The Core Principles of Reliability
🔹 Reliability Starts with Design
A reliable system isn’t just one that works well; it’s one that recovers well. Designing for reliability means considering availability, redundancy, monitoring, and failure recovery from the start.
✅ Key Pillars of Reliability:
Redundancy & Failover – Ensure backup systems take over when failures occur.
Monitoring & Alerts – Detect failures before they impact users.
Failure Isolation – Prevent failures from cascading across services.
Scaling & Load Balancing – Distribute traffic and prevent overload.
🔹 Embrace Failure, Design for Resilience
Cloud environments are inherently unpredictable. Instead of avoiding failure, architect your system to expect and gracefully recover from it.
✅ Best Practice: Use Availability Zones and Availability Sets for high availability.
2. High Availability Strategies in Azure
Azure provides multiple mechanisms to achieve high availability (HA). Let's break them down:
🔹 Availability Zones vs. Availability Sets

📌 Diagram: High Availability in Azure using Availability Zones

🔹 Auto-Scaling for Load Management
Using Azure Virtual Machine Scale Sets (VMSS) and Azure Kubernetes Service (AKS) ensures that your application automatically scales up when demand increases and scales down when demand decreases.
✅ Best Practice: Set up Auto-Scaling Rules to dynamically allocate resources.
📌 Diagram: Horizontal Scaling in Azure

3. Designing for Fault Tolerance and Disaster Recovery
🔹 Key Recovery Metrics: RTO & RPO

✅ Best Practice: Use Geo-Replication and Azure Site Recovery for disaster recovery.
📌 Diagram: Azure Geo-Replication for Disaster Recovery
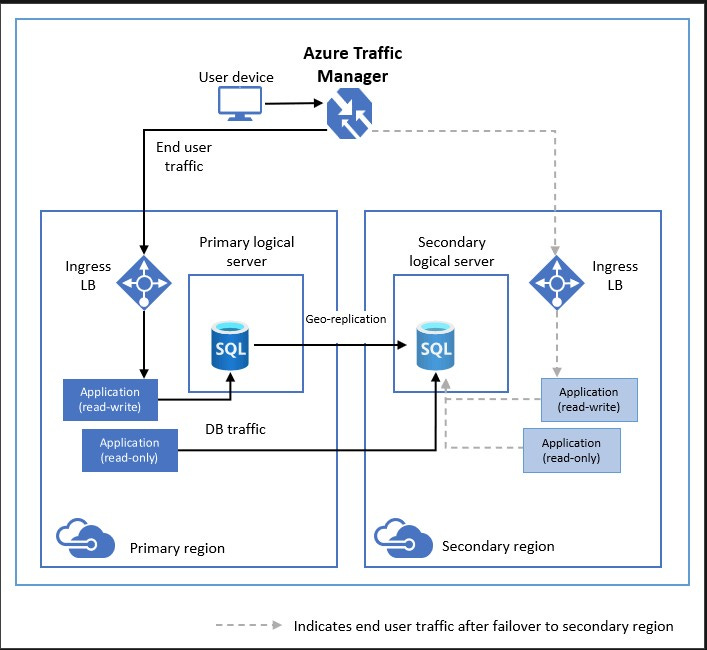
🔹 Backup and Data Resiliency
Protect data using:
Azure Backup – Scheduled backups with long-term retention.
Geo-Redundant Storage (GRS) – Data replication across Azure regions.
Azure Cosmos DB Multi-Region Writes – Ensures zero downtime even if a region fails.
✅ Best Practice: Use Read-Access Geo-Redundant Storage (RA-GRS) for disaster-proof storage.
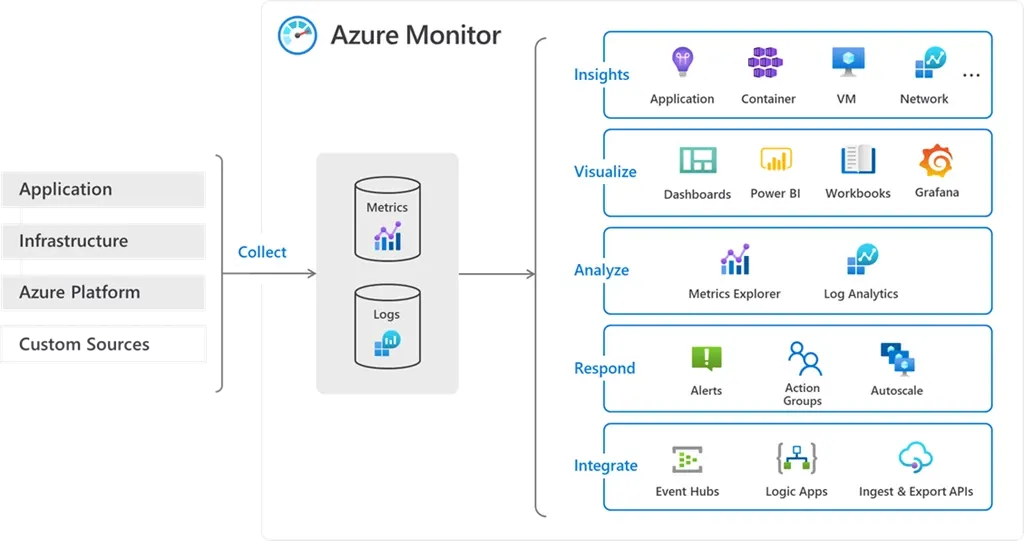
4. Proactive Monitoring & Failure Detection
🔹 Implementing Observability
Monitoring isn’t just about logging errors; it’s about preventing failures before they impact users.
✅ Best Practices for Observability in Azure:
Azure Monitor & Application Insights – Real-time tracking of application health.
Azure Log Analytics – Centralized logging and alerting.
Failure Mode Analysis (FMA) – Identifies potential failure points proactively.
📌 Diagram: Observability in Azure
🔹 Chaos Engineering: Testing for the Unexpected
Don’t wait for failure—simulate failures to test resiliency.
Use Azure Chaos Studio to introduce controlled disruptions and validate fault tolerance.
✅ Best Practice: Regularly conduct failure injection testing to improve reliability.
5. Architecting for Minimal Downtime
🔹 Circuit Breaker & Retry Patterns
Use a circuit breaker pattern to prevent cascading failures and retry logic to recover from transient errors.
✅ Best Practice: Implement Exponential Backoff Retries to handle temporary failures gracefully.
📌 Diagram: Circuit Breaker Pattern

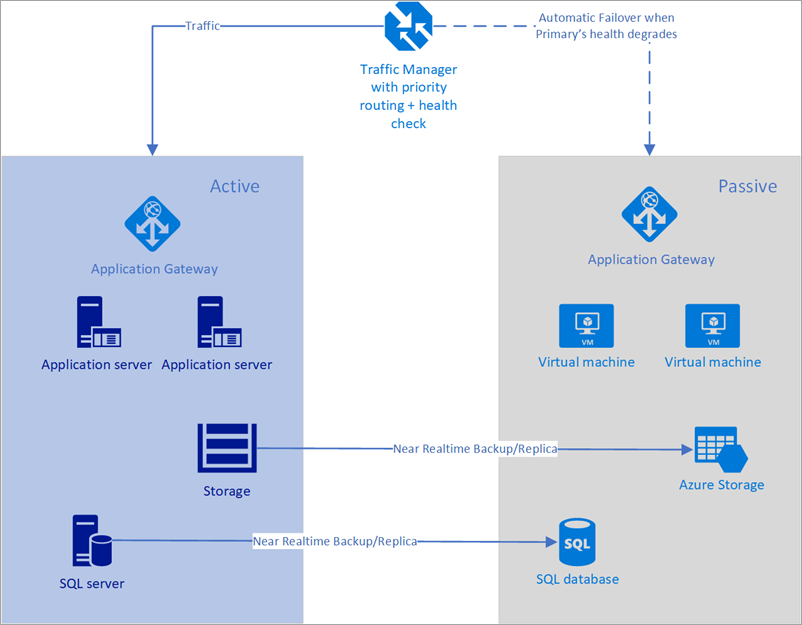
🔹 Traffic Routing & Failover Strategies
Azure Traffic Manager and Front Door enable intelligent traffic routing to maintain uptime even if a region goes down.
✅ Best Practice: Use Priority-based Routing to direct traffic to the healthiest region.
📌 Diagram: Global Traffic Routing using Azure Traffic Manager
6. Real-World Example: ClearBank Enhances Reliability with Azure
ClearBank, a UK-based clearing bank, leverages Microsoft Azure to build a resilient and reliable banking platform. By adopting Azure's robust infrastructure and services, ClearBank ensures high availability and trust for its customers.
Key Strategies Implemented:
Utilizing Availability Zones: ClearBank deploys its services across multiple Azure Availability Zones, ensuring that its applications remain operational even if one zone experiences issues.
Implementing Azure Site Recovery: To prepare for potential disasters, ClearBank uses Azure Site Recovery for efficient failover and recovery, minimizing downtime and data loss.
Continuous Monitoring with Azure Monitor: By employing Azure Monitor, ClearBank gains real-time insights into system performance, allowing for proactive issue detection and resolution.
"Ensuring end-to-end reliability and resiliency is a team effort. We get the tools from Azure, and we set up the systems and processes to put it all together." — Tom Harris, Chief Technology Officer, ClearBank.
7. Conclusion: Your Reliability Roadmap
To build resilient applications on Azure, follow this roadmap:
✅ Design for Failure – Assume failures will happen.
✅ Use Azure’s HA Features – Availability Zones, Auto-Scaling, Geo-Replication.
✅ Monitor & Test Regularly – Azure Monitor, Chaos Engineering, FMA.
✅ Implement Smart Routing – Traffic Manager, Circuit Breaker Pattern.
✅ Ensure Data Resilience – Backups, Multi-Region Databases.
🔹 Final Thought:
"Uptime isn’t just a goal—it’s a responsibility."
💡 What’s Next?
Start applying these principles in your Azure projects!
Share this article with your network if you found it useful!
Podcast link :- Azure Well-Architected Framework: Reliability Best Practices
Happy Reading :)